[CV]
이전까지는 단순히 사진의 객체를 분류하기만 하는 모델을 만들었지만, 이제 픽셀 단위로 객체를 구분해보고자 한다. CV에서는 이를 Semantic segmentation이라고 한다.

사진의 위에는 Image classification, 아래는 Semantic Segmentation이다.
기존 Image classification 모델에서는 주로 마지막 레이어에서 flattening을 하여 하나의 벡터로 바꿨다. 하지만 이는 이미지의 공간 정보를 고려하지 않는다는 말과 동일하다.
semantic segmentation에서 이미지 내의 픽셀에 대한 공간정보는 매우 중요하기 때문에, 이 fully connected layer는 사용하기 힘들다. 그 대신, 1*1 convolutional layer를 사용해 문제를 해결했다.
하지만 FCN에서는 pooling을 사용하여 공간 정보를 줄이는데, 이 때 필연적으로 이미지의 해상도가 계속 낮아지는 문제가 발생한다. 이를 해결하기 위해 unsampling 기법을 사용한다.
이 upsampling을 이용하면 해상도를 원래 이미지로 복원시킬 수 있다.

U-Net

여러 cv task에서 강려한 성능을 보여주는 모델이다. 특징으로는 downsampling과 upsampling이 진행되는 과정이 대칭을 이루고 있다. 또한 대칭되는 부분에서, skip connection을 통해 downsampling 과정의 feature map을 upsampling 과정의 segmentation map에 연결해주고 있다.
코드로 살펴보면 다음과 같다.

downsampling 과정의 코드를 그림과 매핑하면 위와 같다.
Object Detection
픽셀 단위로 객체를 구별하는게 아닌, 물체 하나하나에 박스를 쳐 구분하는 bounding box 예측도 있다. object detection은 classification과 bouding box를 동시에 예측하는 문제이다.

이를 구현하는 대표적인 알고리즘이 두 계열(two-stage detector, single-stage detector)로 발전하고 있는데, 먼저 R-CNN계열이 two-stage detector을 살펴보자.
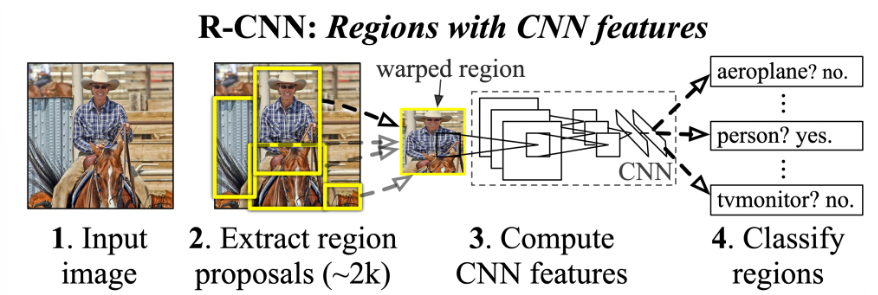
Two-stage detector
간략히 요약하자면, 먼저 객체가 있을만한 후보 영역을 생성한다. (Selective search 등의 방법) 그리고 생성된 영역을 CNN을 이용해 특징을 추출하고, classification도 진행한다.
대략적으로 이런 구조인데, 위 과정에서 객체가 있을 만한 부분 모두에 대해 classification을 수행해야하기 때문에 속도가 매우 느리다. 따라서 fast R-CNN을 사용한다.
어떻게 fast하게 할까? 일반적인 R-CNN은 후보 region마다 모두 CNN을 계산했으니 느린거였기 때문에, fast R-CNN은 먼저 input image에 대한 feature map을 추출하고, 이를 Region of Interest Pooling 기법을 이용해 필요한 부분만 재사용하는 방법을 사용한다.
따라서 한번 input image에 대한 CNN 작업을 끝내면 후에는 재사용할 수 있기에 속도가 향상되는 것이다.
하지만, 성능에 대한 문제가 아직 남았다. 후보 영역을 생성하는 것은 huristic한 방법을 사용하기 떄문이다. 이 region propoasl 까지도 neural network 기반으로 찾으면 어떨까?
그렇게 나온게 Faster R-CNN이다.
One-stage detector
two-stage detector는 먼저 객체가 있을만한 영역을 선정하고(region proposal), 그 다음 classification을 진행하는 두 단계로 나뉘었다.
one-stage detector은 이와 다르게 객체의 위치와 클래스를 동시에 예측한다. 대표적인 모델로 YOLO가 있다.
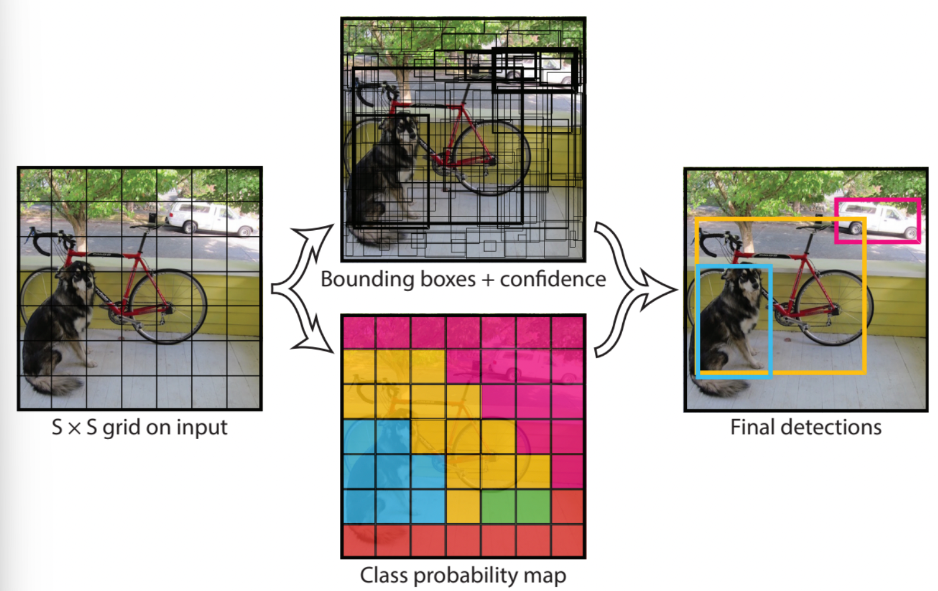
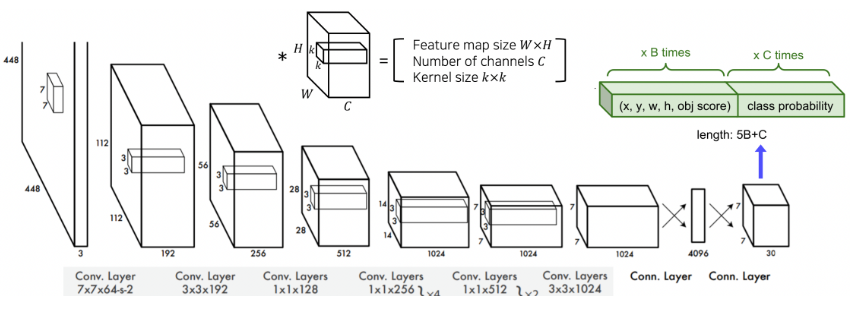
먼저 5*5 그리드로 input image를 분할한 후, 각 그리드에 대해 bounding box 좌표와 confidence score, classification score를 예측하는 형식이다. 구체적인 모델 그림은 아래와 같다.
'KHUDA 활동 아카이브 > CV 기초' 카테고리의 다른 글
| CNN Visualization (CNN의 블랙박스 현상 해결법) (1) | 2023.10.11 |
|---|---|
| [CV] ImageClassification 종류 (0) | 2023.09.20 |
| [CV] Data augmentation 및 Transfer learning (0) | 2023.09.20 |


