우리가 만든 CNN 모델은 어떻게 행동하고, 무엇을 보고 클래스를 판별했을까?
Embedding Feature Analysis (추출된 특성 분석) (high level layer)
Neareast-Neighbor

아래 파란색 박스를 통해(위치도 다르고 자세도 다름) 컨셉을 잘 학습했다는 것을 알 수 있다.
미리 학습된 뉴럴 네트워크 준비 / fc layer 전, 즉 중간 정도에 있는 layer들에 대해 특징 추출하도록 함.
db안에 있는 모든 영상들, 이미지들에 대해서!!
그 특징들은 고차원 데이터일 것이다. 잘 훈련된 모델이라면, 같은 class 영상들의 feature들은 서로 가까이 있을 것이다.
이제 그 모델에 질의 영상을 입력하면, 그 영상의 feature은 자신과 같은 class인 영상들의 feature 근처에 위치하게 될 것이다.
위 방법대로 하면 모델이 정말 잘 classification 했는지 몇 개의 이미지들(위에서는 비슷한 top 6개의 이미지들)을 통해 알 수 있지만, 전체 이미지에 대한 분포는 알 수 없다.
또한, Backbone network를 통해 feature를 추출하면 아주 큰 고차원의 feature를 얻을 수 있지만,
우리의 목적은 visualization, 즉 3차원 이하로 표현해야됨,
고차원 벡터들을 저차원으로 나타내보자, 차원 축소 활용!
t-SNE
고차원 데이터를 2차원으로 잘 표현한다. 클래스들끼리 잘 구분하고 있는 것도 확인 가능하다.
+ 클래스간의 관계도 볼 수 있다. 보면 3,8,5의 군집들은 서로 가까이 있다.
=> 이 모델은 저 숫자들을 유사하다고 보는구나!!
Activation investigation(mid~high level)
: activation map을 이용해 분석
Layer activation
히든 노드에 대한 activation map을 분석
→ 각 노드들을 visualization 해서, 그 노드가 어떤 것을 인식하는지 알아냄.
→ 각 노드별로 어떤 사물/객체를 찾아주는지 알 수 있겠다.

Maximally activation patches
: activation layer에서 가장 큰 값을 가지는 부분 주변을 뜯어내고 원본 이미지에서 그 부분을 보는 방법
ex) 모델의 20번째 layer의 activation map 가장 큰 값들의 주변을, 10개의 강아지 이미지들에 적용시키고 모아봤더니 다 강아지의 코 부분을 나타내고 있더라

⇒ 20번째 activation 노드는 강아지 코를 찾아주는 노드
(국부적인 patch만 보니깐 high level 보다는 mid level에 더 적합하겠다.)
그럼 구체적으로 이를 어떻게 수행할까?
1. 특정 레이어의 특정 채널을 선택한다.
ex) 5번째 레이어의 채널 256개 중 14번째 채널을 선택
2. 예제 이미지들을 백본 네트워크(모델)에 넣어서 선택한 채널을 뽑아낸다
3. 그 채널에서 가장 큰 값을 갖는 위치를 파악하고, 그 값을 나오게 한 receptive field를 계산. 이제 그 field에 대한 부분을 입력 이미지에서 뜯어온다.
그런데... 위 방법들은 모두 특정한 입력 이미지의 어떤 부분이 어떻게 영향을 미치는지밖에 말해주지 않는다.
입력 이미지에 의존하지 않는 방법은 없을까?
Class Visualization
입력 이미지를 사용하지 않고, 네트워크 자체가, 즉 "모델 자체가 기억하고 있는 이미지가 무엇인지 시각화" 하는 방법

위 사진의 아래쪽 강아지 사진을 보면, 강아지 뿐만 아니라 사람 형상도 탐지하고 있음을 볼 수 있다.
→ 데이터셋에 순수 강아지만 있는 사진들 보단 사람들과 함께 있는 사진들이 많구나! 를 알 수 있다.
→ 사람이 없는 강아지 사진도 잘 구별해낼까? 라는 질문을 갖게 함으로써 모델을 더 발전시킬 수 있는 유의미한 과정
- 그럼 저 영상 어떻게 추출해??
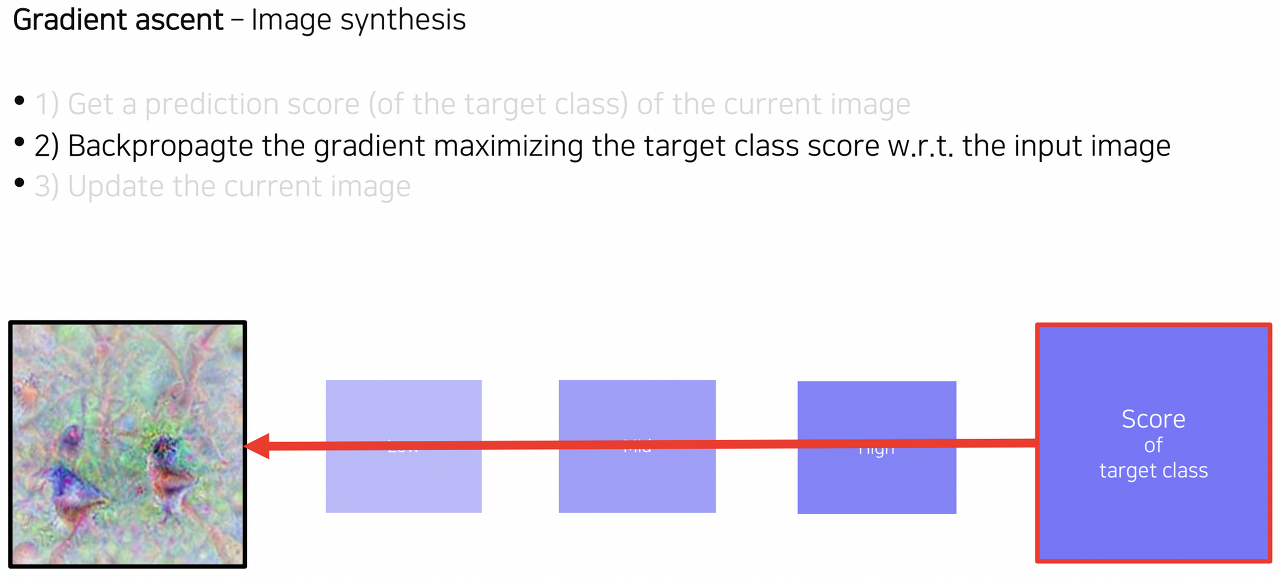
Gradeint ascent
입력이미지가 따로 없다.
→ 모든 픽셀이 0 또는 랜덤하게 짜져있는 이미지를 입력이미지로 한다.

→ 그 이미지가 target class에 최대한 가까워지게 픽셀 값들을 계속 조정한다.
식으로 보면 다음과 같다.
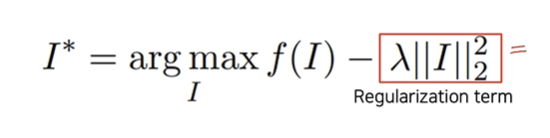
I : input image
f(I) : target class score
입력 이미지가 목표 클래스 스코어(f(I)) 의 점수를 최대로 하게끔 픽셀 값들을 조정한다.
근데 만약, 픽셀값이 255를 넘어가는 그런 픽셀도 존재하는 I가 저 I*로 나온다면??
시각화가 안된다. 이를 막기 위해 regularization term을 놓는다.
또한 특정 픽셀값이 255 이상이 된다는 의미는 과적합 됐다는 의미로도 해석 가능하므로, regularization term을 이용하면 과적합도 막아준다.
regularization term은 각 픽셀들의 제곱의 합이고, 저 식에 의해 분명 regularization term은 작을 수록 좋으므로 픽셀 값들이 작아지게 유도된다. 즉, 픽셀들이 과도하게 높은 값을 갖는 것을 방지해주는 것이다.
여기서 arg I max, 즉 최대가 되게 하는 I를 찾는 것이므로 gradient ascent라고 부름
당연히, 저 class score 최대가 되게 하는 과정은 f(I) 점수가 높게 나오게끔 back propagation을 진행시켜 입력 이미지의 픽셀값들을 계속 업데이트 해나간다.
Class Visualization 예시
"홍학"으로 분류시키는 모델의 Class visualization


"거미"로 분류시키는 모델의 Class visualization

'KHUDA 활동 아카이브 > CV 기초' 카테고리의 다른 글
| [CV] Semantic Segmentation 및 object detection (0) | 2023.09.27 |
|---|---|
| [CV] ImageClassification 종류 (0) | 2023.09.20 |
| [CV] Data augmentation 및 Transfer learning (0) | 2023.09.20 |


