딥러닝 분야는 데이터의 다다익선이 분명한 분야이다.
따라서 한정된 실제 데이터를 최대한 많이 늘리는게 중요한데, 이 떄 사용되는게 data augmentation이다.

만약 밝은 사진으로만 저렇게 동물 사진을 학습했다고 하자. 이때 검은색 바탕의 고양이의 사진을 받으면 모델은 잘 추론하지 못할 수 있다.
따라서 원래 데이터의 밝기를 낮추거나, 색깔을 변화시키는 등의 변화로 데이터셋을 늘려 모델을 더 잘 학습시킬 수 있다.
대표적인 augmentation 기법으로는 Crop, shear, brightness, perspective, rotate, affine 이 있다.
- 밝기 변화
- crop
- affine
augmentation할 때에는 어떤거 쓸건지, 얼마나 세게 할건지 두개의 파라미터가 필요하다.
2. pre-trained 된 모델 활용하기
- Transfer learning : pre-trained된 모델을 이용해 적은 비용으로 새 모델에게 학습시키는 것.
- Approach 1
왼쪽이 pre-trained된 모델이다. 저기서 convolutaion layer만 놔두고, CL 부분만 우리에게 맞게 수정하는게 기본적인 transfer learning의 원리이다
- Approa ch 2
CL 레이어를 바꾸는건 똑같지만, approach1 에서는 convolution layer는 안건드렸던 것과는 달리 여기서는 낮은 학습률로 weght를 건드린다. 성능적으로는 좀더 좋겠지만, 데이터는 더 많이 필요하다.
- knowledge distillation
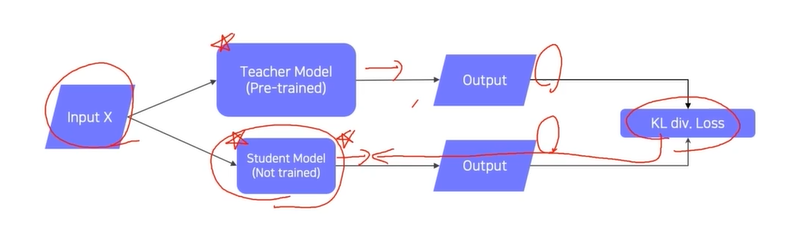
pre-trained 모델을 따라하게하는 방법이다. 레이블이 필요 없으므로 비지도 학습이라고도 볼 수 있다.
- semi-supervised learning
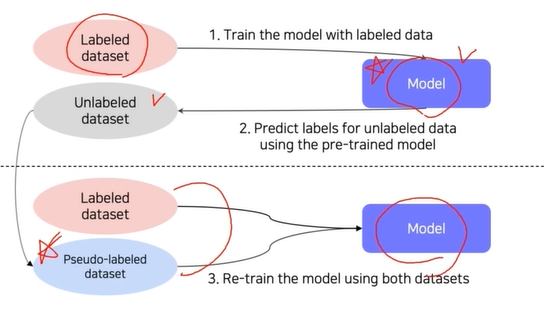
기존 모델을 가지고 psudo-lable을 잔뜩 생성한다. (원래 레이블이 없던 데이터들)
기존 레이블이 있던 데이터와 pseudo lable을 가지고 새 모델을 학습시키는 방법이다.
- 실제로 최근에 가장 좋은 성능을 보이는 이미지 분류 모델은 위 semi-supervised learning을 적극 사용했다. self-learning이라고 부른다. 과정은 아래와 같다.
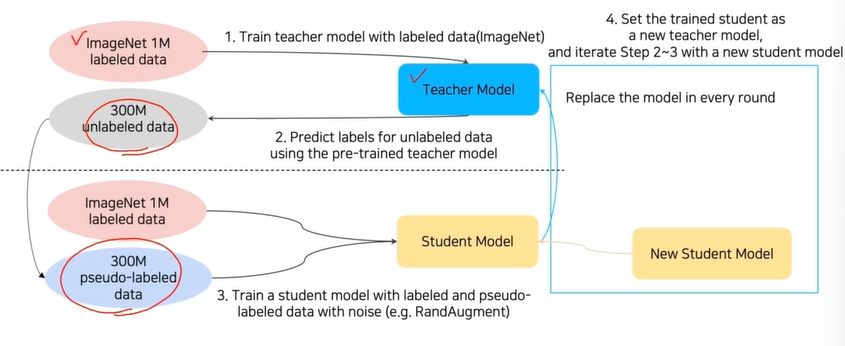
semi-supervised learning 방법을 반복하는 것과 유사하다.
'KHUDA 활동 아카이브 > CV 기초' 카테고리의 다른 글
| CNN Visualization (CNN의 블랙박스 현상 해결법) (1) | 2023.10.11 |
|---|---|
| [CV] Semantic Segmentation 및 object detection (0) | 2023.09.27 |
| [CV] ImageClassification 종류 (0) | 2023.09.20 |


