이 글은 이전 글인 " Ch 1. 나의 첫 머신러닝 - 이 생선의 이름은 무엇인가요? " 에서 이어지는 내용입니다.
앞에서 우리는 도미와 빙어를 구분해주는 머신러닝을 직접 개발해봤습니다.
k-최근접 알고리즘 이라고 불리는걸 활용했죠.
여기서 간단히 용어를 정리해보겠습니다.
입력 : 주어지는 입력 데이터를 의미.
앞의 예시에서는 [길이,무게] 한 쌍이 입력 데이터였습니다.
타깃 : 주어진 입력의 정답을 의미.
앞의 예시에서는 도미가 1, 빙어가 0으로 표기한게 입력에 대한 정답, 즉 타깃이었구요.
훈련 데이터 : 입력과 타깃을 통틀어 부르는 용어.
앞의 예시에서는 " [25.4, 242.0] 는 1 " 이라는게 훈련데이터가 되겠네요.
특성 : 데이터를 표현하는 하나의 성질
앞의 예시에서는 '무게, 길이'가 데이터의 특성이 되겠네요.
앞의 도미, 빙어에 대한 훈련데이터들을 검증할 수 있는 데이터가 존재하지 않았습니다.
그래서 앞의 생선 총 49마리 중 35마리를 훈련데이터, 14마리를 검증 데이터로 설정해보죠.
하지만, 그렇게 설정하고 score()함수를 통해 점수를 매겨보니 0점이 나왔습니다.
이는 훈련데이터 35마리의 생선에는 도미만이 존재하고, 빙어는 존재하기 않기 때문인데요,
이를 샘플링 편향이라고 합니다.
따라서 올바른 훈련데이터를 확보하려면
훈련데이터, 검증데이터 모두 도미와 빙어가 적당히 섞여있어야 하겠죠.
이를 쉽게 하게 해주는 모듈이 numpy입니다.
numpy를 이용해 인덱스를 랜덤으로 정렬시키고,
그중 앞의 35개 생선을 훈련 데이터로,
뒤 14개의 생선을 검증 데이터로 사용하면 샘플링 편향이 발생하지 않겠죠?
코드를 입력해보면 다음과 같습니다.

또한 넘파이는 이미 훈련데이터와 검증데이터를 나누어주는 함수가 존재합니다.
바로 train_test_split() 함수인데요,
여기에 입력과 타깃 데이터를 넣으면,
훈련데이터와 검증데이틀 3:1 비율로 무작위로 나누어줍니다.
하지만 무작위로 나눈다고 해서 반드시 샘플링 편향이 일어나지 않을 것이라는 보장은 없습니다.
특히 데이터의 갯수가 작고, 위 예시같이 도미가 빙어보다 훨씬 많을때는 더 그럴 것이겠죠.
따라서 이 도미와 빙어의 갯수 비율까지 맞추어서 훈련, 검증 데이터를 나누어줄 수 있습니다.
trian_test_split 내에 stratify에 타깃 데이터를 전달하면 됩니다.

자, 이제 수상한 생선이 하나 등장합니다.
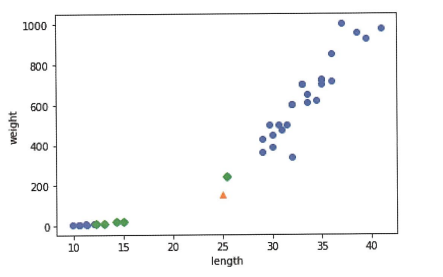
저기에 찍혀있는 노란색 삼각형 점(25cm, 150g) 은 도미일까요, 빙어일까요?
직관적으로는 오른쪽 위, 즉 도미와 가까워 보이기에 우리는 도미라고 예측할 것입니다.
이전 글에서 배운 kn 모델에 저 생선을 대입하면 1이 나올 것입니다.
이러한 문제가 생기는 근본적인 이유는,
x축과 y축의 범위와 단위에 차이가 있기 때문입니다.
x축은 5단위로 끊어져있지만,
y축은 동일한 길이처럼 보이지만 200단위로 끊어져 있죠?
즉 범위에서 차이가 납니다.
우리는 이르
하지만, 실제로 대입해보니 결과는 0, 즉 빙어라고 나왔습니다.
사실 이는 k-최근접 알고리즘이 주변 5개의 이웃 중
과반수 이상이 가지는 클래스로 분류하기 때문입니다.
위 그래프를 살펴보면 초록색 마름모 점이 근처 5개 점입니다.
이 점 중 4개의 점이 빙어이기에, 우리 kn 모델은 이 생선을 빙어로 판단한 것이죠.
실제로 거리를 구해보면 그 괴리감이 확실히 와닿습니다.
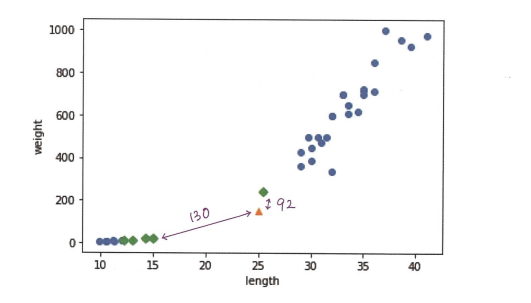
즉, 우리는 x축과 y축이 나타내는 범위가 서로 달라서
이런 문제가 발생함을 알게 되었습니다.
우리는 이를
'두 특성의 스케일이 다르다'
라고 표현할 것입니다.
그러면 우리는 두 특성의 스케일을
동일한 단위로 통합해버리면 되지 않을까요?
즉, 절대적인 값에 집중하기 보다는,
어떤 값이
'평균에서 얼마나 멀리 떨어져있는지'
에 집중해보는 것입니다.
고등학생 시절에 수학을 좀 했었다면
표준편차 라는 개념이 떠오르셨을 겁니다.
이를 이용해 보겠습니다.
즉, 모든 훈련데이터에 대해
무게, 길이 각각의 평균으로 나눈 후
표준편차를 빼주면
우리가 아는 '정규화'가 진행되고,
이는 정확히 우리가 원하는 바와 일치합니다.
이를 코드로 정리해보면 다음과 같습니다.

위 과정을 거침으로써,
무게와 길이는 서로 같은 스케일로 바뀌었습니다.
이제 문제가 일어나지 않기를 기대하고 있습니다.
한번 확인해볼까요?
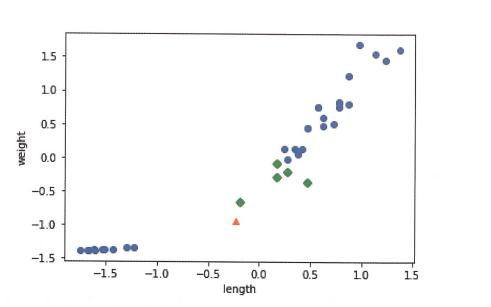
당연히 수상한 생선의 길이, 무게 역시
정규화 과정을 거치고 그래프에 표현해야합니다.
저기서 노란색 삼각형 점이 그 수상한 생선이고,
근처의 5개의 점이 초록색 마름모 점 입니다.
이제서야 우리는 성공적으로 이 생선이 도미로 분류되었다는 것을 알 수 있습니다.
개인적인 궁금증
1. 사이킷런에서 k-최근접 이웃 알고리즘은 근처 5개 이웃까지 조사한다고 했는데, 왜 하필 5개일까?
2. 비슷한 맥락으로, 왜 train_test_split() 함수는 25%만을 테스트 세트로 떼어내는걸까?
3. 표준점수를 이용한 전처리 방법은 유클리드 거리를 이용한 알고리즘 내에서만 유효한걸까?
다른 알고리즘도 이 표준점수를 활용한 전처리를 이용할까?
'KHUDA 활동 아카이브 > Machine Learning 기초' 카테고리의 다른 글
| Ch 6. 비지도 학습 (0) | 2023.08.29 |
|---|---|
| Ch 5. 트리 알고리즘 (0) | 2023.08.22 |
| Ch. 4 다중 분류 알고리즘 (0) | 2023.08.15 |
| Ch 3. 선형회귀 (0) | 2023.08.08 |
| Ch 1. 나의 첫 머신러닝 - 이 생선의 이름은 무엇인가요? (0) | 2023.08.01 |



