로지스틱 회귀
k-최근접 이웃 알고리즘을 이용해 다중분류 해보기
ex) 어떤 생선의 무게, 길이, 대각선 길이, 높이, 너비 값을 이용해
도미, 잉어, 송어, 대구, 농어, 강꼬치고기, 빙어
7종류의 생선 중 어떤 생선인지 맞춰보자.
늘 하던대로 , train_test_split을 이용해 훈련셋과 테스트셋을 분리하고 StandardScaler 변환기 클래스를 이용해 전처리까지.
k-최근접 분류 클래스는 KNeighborsClassifier이다. fit 한 후 앞에 5개의 score값을 측정하니,

이렇게 확률이 나오긴 한다. 하지만 확률이 너무 이산적이다.
당연하다. k-최근접 분류에서 이웃을 3개로 한정지었기 때문. 그래서 분모가 항상 3이기에 위와 같은 0.6667 확률이 나온거.
연속적인 확률을 얻고싶다 => 로지스틱 회귀!
이렇게 각각의 특성에 가중치값을 설정해놓고, 모두 더한값을 z라 하자. 이 z가 클수록 1에 가까운 확률이 되고, 작을수록 0에 가까운 확률이 되면 좋겠다. 대충 그래프로 그려보면 이런 모양.
이를 시그모이드 그래프라고 하자. 식도 있으면 좋겠네. 식은 아래와 같다.
이러면 연속적인 확률이 나올 수 있겠다. 그럼 이걸로 먼저 이진분류부터 해볼까?
저 시그모이드 함수에 z값을 넣으면 확률이 나온다. 이때 두 개중에 확률이 1에 가까운 놈이 두개 중 하나의 특성인거다.
코드로는 다음과 같이 구현 가능
이 lr 모델을 이용해서 train 데이터의 첫 5개 샘플을 예측해보면?
이렇게 확률까지 잘 보여준다. 가중치도 볼 수 있다.
로지스틱 회귀를 이용해 이진분류를 해봤으니, 다중분류도 해보자!
다중분류를 할 때에는 추가 설정을 해주는게 좋다.
로지스틱 회귀도 계속 반복 작업을 한단다. 얼마나 반복할지(max_iter), 규제는 어느정도 할지(C) 파라미터로 설정해주자.
이때 규제는 릿지 회귀를 사용하고, C값이 커질수록 규제가 완화된다고 한다. 기본값은 1이다. C=20으로 해줘서 규제를 좀 풀어주자.
역시 높은 점수가 나왔다.
그럼 확률도 봐볼까?
아까 이진분류는 사실 시그모이드 함수값 0.5를 기준으로 크면 이거, 작으면 저거로 결정했었다.
다중분류는? 사실 소프트맥스 함수를 이용한다.
이 e_sum을 분모로 하고, 각각의 e^(zn)을 분자로 해서 확률로 나타낸다.
왜 하필 e를 사용할까?
쉽게 말하자면, 저 소프트맥스 함수는 시그모이드로부터 유도될 때 e^x가 나오기도 하고, e^x는 미분하기도 편해서이다.
확률적 경사 하강법
이름에서도 알 수 있듯, 경사를 하강하는 방법이다.
정확히는, 훈련 데이터 샘플에서 '확률적'으로, 즉 랜덤으로 샘플들을 뽑아 훈련한다.
뭘 어떻게 훈련하냐?
바로 최적의 '경사'를 '하강' 하는 방법을 훈련한다.
여기서 말하는 경사를 하강한다는 의미는 가장 손실이 적은 모델을 찾는다는 의미이다.
훈련 데이터 샘플을 한 번 모두 사용해서 학습 했다면 이를 1에포크가 끝났다고 부른다.
여기사 가장 손실이 적다 라는 것을 어떻게 판단할 수 있을까?
머신러닝의 손실이 어느정도인지 나타내주는 손실함수 라는게 존재한다.
손실함수 라는 의미에 맞게, 손실이 크면 클수록 함숫값이 크고, 손실이 작다면 함숫값도 작다.
손실 함수는 기본적으로 확률을 이용한다. 확률은 0과 1사이에 있고, 손실함수는 그 확률에 따라 함숫값이 바뀌면 좋기에 로그함수를 사용한다.
이진 분류에서 사용되는 손실함수를 로지스틱 손실함수,
다중분류에서 사용되는 손실함수를 크로스엔트로피 손실함수라고 부른다.
과대/과소적합 판단
경사하강법에서도 역시 과대적합, 과소적합이 존재할 수 있다.
원리는 에포크의 횟수이다. 즉 너무 많이 반복학습 시킨다면 과대적합이 일어나고, 너무 적게 시킨다면 과소적합이 발생하는 것이다.
그래서 적당한 에포크 횟수를 찾을 필요가 있다.
그래서 약 300번의 에포크를 진행하면서, 각 에포크에서의 훈련셋 점수와 테스트셋 점수를 비교해보자.

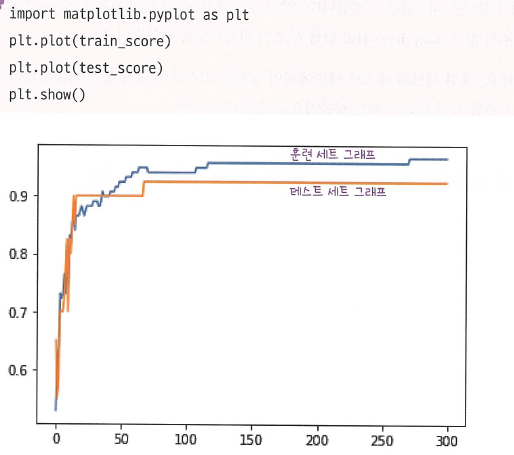
훈련세트와 테스트세트가 충분히 큼과 동시에 차이가 많이 나지 않을 때가 가장 적당한 에포크 횟수이다.
육안상으로는 100번이 적당할 듯 하다. 따라서 100번이 적당한 에포크 횟수라고 할 수 있다.
- 수가 클수록 1에 근접하는게 로지스틱 회귀인데, 그 그래프를 보면 적당한 곡선으로 되어있다. 이때 상황에 따라 시그모이드 함수의 변곡점이 유동적으로 달라질 필요성이 있어 보이는데, 이를 조절할 수 있는 방법? + 최적의 변곡점 위치를 찾는 방법?
- LogiscticRegression 클래스가 기본적으로 반복적인 알고리즘을 사용한다던데, 무슨 의미인가? train_scaled와 train_target 데이터들을 1번만 학습하는 것이 아닌, max_iter만큼 반복적으로 학습한다는 의미인가?
- 소프트맥스 함수는 왜 굳이 e를 밑으로 하는 지수함수를 이용할까? 단순히 z1부터 z7까지 더한 수를 분모로, z1,z2…. 각각을 분자로 두어도 확률의 합이 1이 되는데 이 방법은 어떤 문제가 있나?
'KHUDA 활동 아카이브 > Machine Learning 기초' 카테고리의 다른 글
| Ch 6. 비지도 학습 (0) | 2023.08.29 |
|---|---|
| Ch 5. 트리 알고리즘 (0) | 2023.08.22 |
| Ch 3. 선형회귀 (0) | 2023.08.08 |
| Ch 2. 데이터 다루기 - 수상한 생선을 조심해라! (0) | 2023.08.01 |
| Ch 1. 나의 첫 머신러닝 - 이 생선의 이름은 무엇인가요? (0) | 2023.08.01 |



