앞서 다룬 회귀와는 또 다른 알고리즘을 알아보자.
이번 예시는 와인 분류이다.
알코올, 당도, pH를 이용해 레드 와인인지 화이트 와인인지 구분하는 것이다.
얼핏보면 특성이 3개이고 이진분류이므로, 특성 스케일 값을 표준점수로 전처리해서 로지스틱 회귀를 사용하면 해결될 것이라는 생각이 든다.
한번 해보면?
data = wine[['alcohol', 'sugar', 'pH']].to_numpy()
target = wine[['class']].to_numpy()
from sklearn.preprocessing import StandardScaler
ss = StandardScaler()
ss.fit(train_input)
train_scaled = ss.transform(train_input)
test_scaled = ss.transform(test_input)
from sklearn.linear_model import LogisticRegression
lr = LogisticRegression()
lr.fit(train_scaled, train_target)
print(lr.score(train_scaled, train_target))
print(lr.score(test_scaled, test_target))

점수가 많이 낮다. 보통 95점 이상은 넘겨야 쓸만하다던데...
왜 낮은지는 모르겠으나, 한번 다른 방법을 사용해보자. 이때 나오는게 결정트리이다.
결정트리는 노드로 이뤄져있고, 말 그대로 트리형태를 가지고 있다.

얘 역시 사이킷런에서 지원한다. 사용방법은 역시 동일하다.
#결정트리
from sklearn.tree import DecisionTreeClassifier
dt = DecisionTreeClassifier(random_state=42)
dt.fit(train_scaled, train_target)
print(dt.score(train_scaled, train_target))
print(dt.score(test_scaled, test_target))

확실히 점수가 엄청 오르긴 했지만, 훈련셋 점수가 너무 높으므로 과대적합된거 같다. 아무튼, 대충 어떤 구조인지 살펴보면?
import matplotlib.pyplot as plt
from sklearn.tree import plot_tree
plt.figure(figsize=(10,7))
plot_tree(dt)
plt.show()

아주 혼란스러운 트리가 나오게 된다. 트리의 깊이가 너무 깊어서 그런거 같기 때문에, 깊이를 1로 줄여보자.
그리고 각 노드는 특성에 따라 구분된다 했으므로 특성 이름도 붙여주자.
plt.figure(figsize=(10,7))
plot_tree(dt, max_depth=1, filled=True, feature_names=['alcohol','sugar','pH'])
plt.show()

맨 위에가 테스트 조건, 즉 구분 기준이다.
그리고 그 밑 gini는 지니 불순도라고 한다. 지니 불순도는 다음과 같이 정의된다.

쉽게 말하자면, 지니 불순도가 낮을수록 한쪽 클래스에 치우쳐져 있는, 비교적 순수한 클래스라는 의미이다.
노드를 거칠수록 각 집단이 한쪽 클래스에 치우쳐져 있어야 구분이 확실히 되는 것이므로, 부모의 지니 불순도 대비 자식의 지니 불순도가 더 낮다면 좋은 모델인 것이다.
따라서 결정 트리는 부모 노드와 자식 노드의 불순도 차이가 가능한 크도록 트리를 성장시킨다.
이 부모와 자식간의 불순도 차이를 정보 이득이라고 부른다.
맨 처음의 트리를 살펴보면 너무 트리의 깊이가 깊으므로, 이번에는 트리 깊이를 3으로 제한해보자.
dt = DecisionTreeClassifier(max_depth=3, random_state=42)
dt.fit(train_scaled, train_target)
print(dt.score(train_scaled, train_target))
print(dt.score(test_scaled, test_target))

나름 높아지긴 했지만, 여전히 아쉬운 수치긴 하다. 아무튼 이 트리도 plot을 이용해 시각화 해보자.
하기 전에, 이 결정 트리는 결국 클래스의 비율로 분류되는 것이기 때문에 전처리는 사실 필요 없다. 그래서 train_scaled가 아닌 원래의 train_input을 사용하자.
dt = DecisionTreeClassifier(max_depth=3, random_state=42)
dt.fit(train_input, train_target)
print(dt.score(train_input, train_target))
print(dt.score(test_input, test_target))
plt.figure(figsize=(20,15))
plot_tree(dt, max_depth=3, filled=True, feature_names=['alcohol','sugar','pH'])
plt.show()

이러면 나름 해석하기도 쉬울거 같다. 추가적으로 어떤 특성이 중요한지, 특성 중요도도 나타내는 값도 있다.
print(dt.feature_importances_)

중간인 sugar(당도)가 가장 중요한가보다. 즉, 결정 트리는 특성 선택에도 활용할 수 있을거 같다.
결정트리 뿐만 아니라 여러 알고리즘에는 하이퍼 파라미터가 존재했다.
최적의 값을 구하려면 여러 값을 넣어보고 반복해서 테스트값을 확인했어야하는데, 그러면 테스트 값에 과대적합 되버릴 수 있다.
그래서 테스트 세트에서 또 검증 세트를 새로 만들고, 얘로 테스트를 거친다음 최종 테스트에만 테스트 세트를 사용할 수 있다.
그런데 검증 세트를 만들면 저절로 테스트 세트가 줄어드는데, 이것 마저도 불만이다. 그러면 훈련 세트를 n등분하고, 등분한 n개의 훈련 세트 하나하나를 모두 검증세트로 써보아서 n번 모델을 평가하면 어떨까?
이것이 교차검증의 핵심 아이디어이다.
아무튼, 우리의 목표는 하이퍼 파라미터의 튜닝이다. 그런데 하이퍼 파라미터 각각이 모두 독립이라는 보장은 없다. 그래서 각 하이퍼 파라미터들을 동시에 바꿔가며 최적의 값을 찾는 과정이 필요하다.
사이킷런에서는 이를 구현해주는 그리드 서치를 제공한다. 코드로 보면 다음과 같다.
#grid 서치
from sklearn.model_selection import GridSearchCV
params = {'min_impurity_decrease' : [0.0001, 0.0002, 0.0003, 0.0004, 0.0005]}
gs = GridSearchCV(DecisionTreeClassifier(random_state=42), params, n_jobs=-1)
이렇게 하면 gs 객체 안에서 저 min_impurity_decrease 파라미터가 각각 저 5번일 때의 값들이 다 나온다.
여러가지 특성일 떄는?
params = {'min_impurity_decrease' : uniform(0.0001, 0.001),
'max_depth' : randint(20,50),
'min_samples_split' : randint(2,25),
'min_samples_leaf' : randint(1,25),
}
from sklearn.model_selection import RandomizedSearchCV
gs = RandomizedSearchCV(DecisionTreeClassifier(random_state=42), params, n_iter=100, n_jobs=-1, random_state=42)
gs.fit(train_input, train_target)
이렇게 활용하면 된다. 위에서는 랜덤변수를 이용했다. 언제 가장 점수가 높은지 확인해보면,
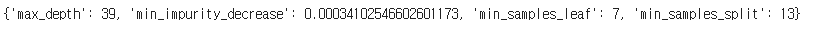
이때라고 한다.
위에서 활용한 결정 트리를 여러번 반복 학습시키면 어떨까?
이 아이디어에서 나온게 바로 앙상블 학습이다.
앙상블 학습은 주로 정형 데이터에서 가장 뛰어난 성능을 낸다고 알려져있다.
대표적인 앙상블 학습은 다음과 같다.
1. 랜덤 포레스트 : 부트스트랩 샘플(훈련 데이터 샘플에서 복원 추출) 사용
from sklearn.model_selection import cross_validate
from sklearn.ensemble import RandomForestClassifier
import numpy as np
rf = RandomForestClassifier(n_jobs=-1, random_state=42)
scores = cross_validate(rf, train_input, train_target, return_train_score=True, n_jobs=-1)
print(np.mean(scores['train_score']), np.mean(scores['test_score']))

2. 엑스트라 트리 : 결정 트리의 노드를 랜덤하게 분할
from sklearn.ensemble import ExtraTreesClassifier
et = ExtraTreesClassifier(n_jobs=-1, random_state=42)
scores = cross_validate(et, train_input, train_target, return_train_score=True, n_jobs=-1)
print(np.mean(scores['test_score']), np.mean(scores['train_score']))

3. 그레디언트 부스팅 : 트리의 손실을 보완하는 식으로, 얕은 결정트리를 연속해서 추
from sklearn.ensemble import GradientBoostingClassifier
gb = GradientBoostingClassifier(random_state=42)
scores = cross_validate(gb, train_input, train_target, return_train_score=True, n_jobs=-1)
print(np.mean(scores['test_score']), np.mean(scores['train_score']))

4. 히스토그램 기반 그레디언트 부스팅 : 훈련 데이터를 256개의 정수 구간으로 나
from sklearn.experimental import enable_hist_gradient_boosting
from sklearn.ensemble import HistGradientBoostingClassifier
hgb = HistGradientBoostingClassifier(random_state=42)
scores = cross_validate(hgb, train_input, train_target, return_train_score=True)
print(np.mean(scores['test_score']), np.mean(scores['train_score']))




